วิวัฒนาการของ OCR จากการอ่านตัวอักษรสู่ AI อัจฉริยะ - Xtends
Last updated: 27 พ.ย. 2567 | 362 จำนวนผู้เข้าชม |

วิวัฒนาการของ OCR จากการอ่านตัวอักษรสู่ AI อัจฉริยะ
OCR (Optical Character Recognition) คือเทคโนโลยีที่ช่วยแปลงข้อมูลจากเอกสารหรือภาพให้อยู่ในรูปแบบข้อความดิจิทัล ซึ่งได้รับการพัฒนาอย่างต่อเนื่องตั้งแต่เริ่มต้นจนถึงยุคของ AI อัจฉริยะ วันนี้เราจะพาคุณสำรวจวิวัฒนาการของ OCR ตั้งแต่จุดเริ่มต้นไปจนถึงความก้าวหน้าล่าสุด

ภาพจาก: https://runsystem.net/en/2024/03/26/ocr-technology-helps-businesses-save-time/
1. จุดเริ่มต้น: การอ่านตัวอักษรอย่างง่าย
- ยุคก่อนคอมพิวเตอร์ (1920-1950)

ย้อนกลับไปในยุคก่อนการกำเนิดของคอมพิวเตอร์ เทคโนโลยี OCR (Optical Character Recognition) เริ่มต้นมาจากความพยายามในการพัฒนาเครื่องมือที่สามารถช่วยเหลือมนุษย์ในการอ่านข้อมูลจากตัวอักษรบนกระดาษหรือวัสดุอื่น ๆ โดยเฉพาะเพื่อช่วยเหลือผู้พิการทางสายตาและเพิ่มประสิทธิภาพในกระบวนการจัดการข้อมูล โดยมีพัฒนาการสำคัญดังนี้
การแปลงข้อความเป็นเสียง (Optophone)
Optophone เป็นหนึ่งในเครื่องมือแรก ๆ ที่ถือเป็นจุดเริ่มต้นของเทคโนโลยี OCR ออกแบบโดย Edmund Fournier d'Albe นักวิทยาศาสตร์ชาวอังกฤษในปี 1920 เครื่องมือนี้ถูกพัฒนาขึ้นเพื่อแปลงตัวอักษรเป็นเสียง โดยใช้แสงสะท้อนจากตัวอักษรบนพื้นผิว แม้ว่า Optophone จะไม่ได้มีความสามารถในการจดจำตัวอักษร แต่สามารถสร้างเสียงที่แตกต่างกันตามรูปแบบของตัวอักษร อย่างไรก็ตาม เครื่องมือนี้มีข้อจำกัดในด้านความเร็วและเหมาะสำหรับการใช้งานเฉพาะกลุ่มเท่านั้น
การพัฒนาเทคโนโลยีออปโตเมคานิคส์ (Opto-Mechanical Technology)
ในช่วงปลายทศวรรษ 1930 นักวิจัยเริ่มนำเซลล์โฟโตอิเล็กทริก (Photoelectric Cell) มาใช้ในการพัฒนาระบบที่สามารถตรวจจับและจดจำรูปแบบของตัวอักษร แนวคิดนี้กลายเป็นรากฐานสำคัญของเทคโนโลยี OCR โดยมีการออกแบบให้เครื่องจักรสามารถ "จับคู่" ตัวอักษรที่สแกนเข้ากับรูปแบบตัวอักษรที่บันทึกไว้ล่วงหน้า
การอ่านตัวอักษรเพื่อช่วยผู้พิการ
Emanuel Goldberg นักวิทยาศาสตร์ชาวเยอรมัน ได้พัฒนาเครื่องมือที่สามารถอ่านตัวอักษรและแปลงข้อมูลเป็นรหัส Morse นับเป็นต้นแบบที่ผสานเทคโนโลยีการจดจำตัวอักษรเข้ากับการแปลงข้อมูลเพื่อประยุกต์ใช้งานในด้านการสื่อสารอย่างมีประสิทธิภาพ
การจดสิทธิบัตรระบบ OCR ครั้งแรก
ในปี 1949 David H. Shepard นักประดิษฐ์ชาวอเมริกัน ได้พัฒนาระบบ OCR เครื่องแรกของโลกและจดสิทธิบัตรเป็นครั้งแรก เครื่องนี้ถูกออกแบบเพื่อแปลงข้อความจากตัวอักษรพิมพ์ธรรมดาให้สามารถประมวลผลโดยเครื่องจักรได้ โดยอาศัยหลักการจับคู่รูปแบบตัวอักษร (Pattern Matching) เป็นพื้นฐานสำคัญในการทำงาน
- การเกิดของ OCR เชิงพาณิชย์ (1960-1980)

ในช่วงนี้ OCR ได้รับการออกแบบให้รองรับการประมวลผลข้อมูลจากเอกสารลายพิมพ์ เช่น เช็คธนาคาร ใบเสร็จ และใบสั่งซื้อ โดยอาศัยเทคโนโลยีสำคัญอย่างเซ็นเซอร์ตรวจจับลำแสง (Light Sensors) ซึ่งช่วยตรวจจับความแตกต่างของสีและความเข้มของหมึกตัวอักษร ทำให้สามารถจดจำตัวอักษรบนกระดาษธรรมดาได้อย่างแม่นยำยิ่งขึ้น นอกจากนี้ ระบบ OCR ยังคงใช้หลักการเปรียบเทียบตัวอักษรที่สแกนกับรูปแบบตัวอักษร (Template Matching) ที่กำหนดไว้ล่วงหน้าเพื่อเพิ่มประสิทธิภาพในการจดจำข้อมูล
OCR-A พัฒนาขึ้นในปี 1966 โดย American National Standards Institute (ANSI) ถูกออกแบบมาเพื่อให้เหมาะสมกับการอ่านของเครื่องจักร โดยตัวอักษรมีรูปทรงเหลี่ยมที่ชัดเจน เรียบง่าย และง่ายต่อการประมวลผล
OCR-B ถูกออกแบบโดย Adrian Frutiger เพื่อรองรับการใช้งานที่ต้องการทั้งความสวยงามและความง่ายในการอ่านของเครื่องจักร ตัวอักษรประเภทนี้ได้รับความนิยมอย่างแพร่หลายในธนาคารและธุรกรรมทางการเงิน
ธนาคารเริ่มนำระบบ Magnetic Ink Character Recognition (MICR) มาใช้ ซึ่งสามารถอ่านตัวอักษรที่พิมพ์ด้วยหมึกแม่เหล็ก MICR ช่วยให้ OCR สามารถอ่านตัวเลขในเช็คหรือเอกสารทางการเงินที่พิมพ์ด้วยฟอนต์พิเศษ เช่น E-13B ได้อย่างแม่นยำ
ในช่วงทศวรรษ 1960 บริษัท RCA ได้พัฒนาและเปิดตัวเครื่อง OCR รุ่นแรกสำหรับการใช้งานในองค์กร ซึ่งรองรับการสแกนเอกสารและการดึงข้อมูลตัวอักษรโดยอัตโนมัติ ต่อมาในทศวรรษ 1970 บริษัท IBM ได้พัฒนาระบบ OCR เชิงพาณิชย์ที่สามารถอ่านฟอนต์ได้หลากหลาย โดยถูกนำไปใช้ในภาคธุรกิจและหน่วยงานราชการ เช่น การสแกนเอกสารภาษี
OCR เริ่มถูกนำไปใช้ในการอ่านตัวเลขบัญชีในเช็คและการประมวลผลเอกสารทางการเงินในอุตสาหกรรมธนาคารและการเงิน นอกจากนี้ยังถูกใช้ในการสแกนที่อยู่และรหัสไปรษณีย์บนจดหมาย รวมถึงการสแกนและจัดเก็บข้อมูลจากเอกสารสำคัญในหน่วยงานราชการ เช่น ใบทะเบียนราษฎร์
- การประยุกต์ใช้ Machine Learning ขั้นพื้นฐาน

ระบบ OCR แบบดั้งเดิมใช้การจับคู่รูปแบบตัวอักษรกับแม่แบบที่กำหนดไว้ล่วงหน้า (Predefined Templates) ซึ่งมีข้อจำกัดในการรองรับฟอนต์ที่หลากหลาย ตัวอักษรที่เบลอ หรือเอกสารที่มีคุณภาพต่ำ แต่ด้วยการใช้ Machine Learning, OCR สามารถเรียนรู้และปรับตัวเข้ากับรูปแบบตัวอักษรใหม่ๆ ได้โดยไม่ต้องสร้างแม่แบบล่วงหน้า
Neural Networks รุ่นแรก เช่น Perceptron ได้ถูกนำมาใช้ในการแยกแยะลักษณะของตัวอักษร เช่น เส้นตรง, โค้ง, และมุม ในยุคนี้ โมเดลจะเรียนรู้ลักษณะเฉพาะของตัวอักษรแต่ละตัวผ่านกระบวนการฝึก (Training) โดยใช้ข้อมูลตัวอักษรจำนวนมาก ซึ่งทำให้สามารถรองรับตัวอักษรหลากหลายรูปแบบและภาษาต่างๆ และปรับปรุงความสามารถในการจดจำตัวอักษรได้ดีขึ้น แม้ในกรณีที่ภาพไม่ชัดเจน
HMMs ถูกนำมาใช้ใน OCR เพื่อจดจำลำดับของตัวอักษร โดยพิจารณาความสัมพันธ์ระหว่างตัวอักษรแต่ละตัว ซึ่งช่วยให้ OCR ไม่เพียงแค่สามารถระบุตัวอักษรแต่ละตัวได้ แต่ยังสามารถเข้าใจโครงสร้างของคำหรือข้อความในบริบทได้อย่างถูกต้อง
- การใช้ Deep Learning เพื่อเพิ่มความแม่นยำ

CNN ถูกนำมาใช้ในการประมวลผลภาพและแยกคุณลักษณะ (Features) ที่ซับซ้อนของตัวอักษร เช่น เส้นโค้งหรือพื้นผิวของภาพ ซึ่งช่วยปรับปรุงความแม่นยำของ OCR โดยเฉพาะในเอกสารที่มีคุณภาพต่ำ
Recurrent Neural Networks (RNNs)
โมเดลแบบ Long Short-Term Memory (LSTM) ช่วยให้ OCR สามารถจดจำตัวอักษรที่มีความสัมพันธ์กันในลำดับข้อความได้อย่างมีประสิทธิภาพยิ่งขึ้น
- OCR แบบอัจฉริยะ (Intelligent OCR)

การผสาน AI และ NLP เข้ากับ OCR ช่วยให้ระบบสามารถเข้าใจบริบทของข้อความได้ดีขึ้น เช่น การวิเคราะห์เนื้อหาในเอกสารทางกฎหมาย
การจดจำลายมือ (Handwriting Recognition)
เทคโนโลยี AI Handwriting Recognition ได้รับการพัฒนาเพื่อสามารถจดจำลายมือที่เขียนด้วยมือในรูปแบบที่หลากหลาย
- OCR บนคลาวด์และการทำงานแบบเรียลไทม์
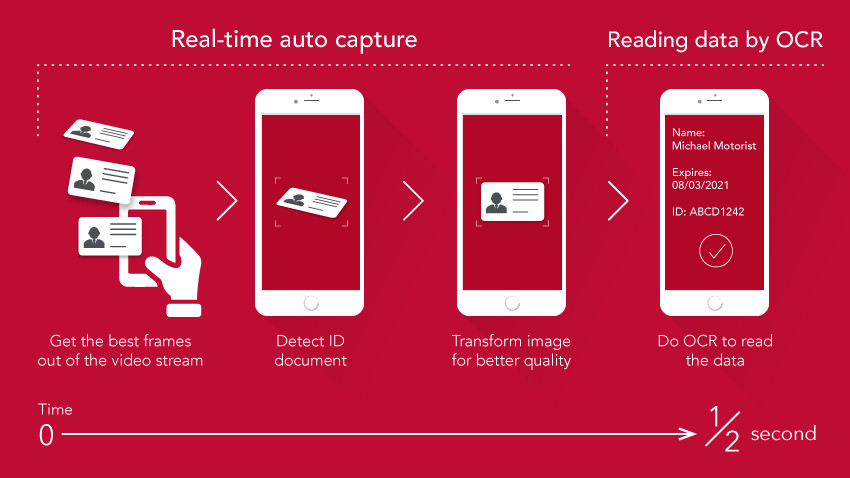
Real-Time OCR
ปัจจุบัน OCR สามารถจดจำข้อความในวิดีโอและภาพได้แบบเรียลไทม์ และถูกนำไปใช้ในแอปพลิเคชันต่างๆ เช่น Google Translate ที่สามารถแปลข้อความจากป้ายได้ทันที
4. ผลกระทบของ OCR ในยุค AI
เทคโนโลยี OCR (Optical Character Recognition) ในยุคที่ผสานกับ AI ได้มีการเปลี่ยนแปลงกระบวนการทำงานในหลากหลายด้าน ตั้งแต่ธุรกิจ การศึกษา ไปจนถึงชีวิตประจำวัน ความก้าวหน้าในด้านความแม่นยำ ความเร็ว และความสามารถในการเข้าใจข้อมูลเชิงลึกได้นำไปสู่ผลกระทบสำคัญในหลากหลายมิติ โดยมีพัฒนาการสำคัญดังนี้
- การเพิ่มประสิทธิภาพในภาคธุรกิจ

การประมวลผลเอกสาร
OCR ช่วยอ่านข้อมูลจากใบแจ้งหนี้ สัญญา และบิลค่าใช้จ่ายโดยอัตโนมัติ ซึ่งช่วยลดเวลาที่ใช้ในกระบวนการป้อนข้อมูลด้วยตนเอง
การจัดการข้อมูลขนาดใหญ่ (Big Data)
OCR สามารถสกัดข้อมูลจากเอกสารจำนวนมหาศาลเพื่อการวิเคราะห์เชิงลึก และสนับสนุนการตัดสินใจทางธุรกิจแบบเรียลไทม์
- การพัฒนาด้านการศึกษาและการเข้าถึงความรู้

การดิจิไทซ์เอกสารทางการศึกษา
OCR ช่วยสแกนหนังสือและบทความเก่าเพื่อให้สามารถนำมาใช้งานในรูปแบบออนไลน์ และรองรับการค้นหาข้อมูลจากข้อความในเอกสารดิจิทัล
การช่วยเหลือผู้พิการทางสายตา
การผสาน OCR กับ Text-to-Speech (TTS) ช่วยแปลงข้อความในเอกสารให้เป็นเสียง เพื่อช่วยให้ผู้พิการทางสายตาสามารถเข้าถึงข้อมูลได้
5. อนาคตของ OCR
- OCR ที่เข้าใจและเรียนรู้ด้วยตัวเอง (Self-Learning OCR)

ในอนาคต เทคโนโลยี OCR จะสามารถเรียนรู้จากข้อมูลใหม่ๆ ได้โดยอัตโนมัติ โดยไม่ต้องการการฝึกสอนเพิ่มเติม ด้วยการใช้ Reinforcement Learning และ Active Learning ซึ่งช่วยให้ OCR ปรับปรุงความแม่นยำเมื่อเผชิญกับข้อมูลที่หลากหลาย
- การรองรับข้อมูลที่ซับซ้อนมากขึ้น

ในอนาคต OCR จะสามารถจัดการกับข้อมูลที่ซับซ้อนได้มากขึ้น เช่น การจดจำลายมือที่ไม่เป็นระเบียบ หรือการรองรับตัวอักษรหลากหลายรูปแบบในเอกสารเดียวกัน รวมถึงการสกัดข้อมูลจากตาราง, กราฟ, ภาพถ่าย หรือแผนที่
- การเพิ่มความปลอดภัยและการปกป้องข้อมูล (Secure OCR)

ในอนาคต OCR จะให้ความสำคัญกับความปลอดภัยของข้อมูลมากขึ้น โดยจะมีการใช้การเข้ารหัสข้อมูลและการประมวลผลข้อมูลในระดับโลคอลเพื่อลดความเสี่ยงในการรั่วไหลของข้อมูล

